Coursera.org 에서 Michigan University의 Applied Data Science with Python의 강의를 토대로 정리한 내용입니다.
Assignment2를 간신히 pass하고 이제 subplot으로 넘어왔네요.. 한번 자랑하고 갈게요! ㅋㅋ
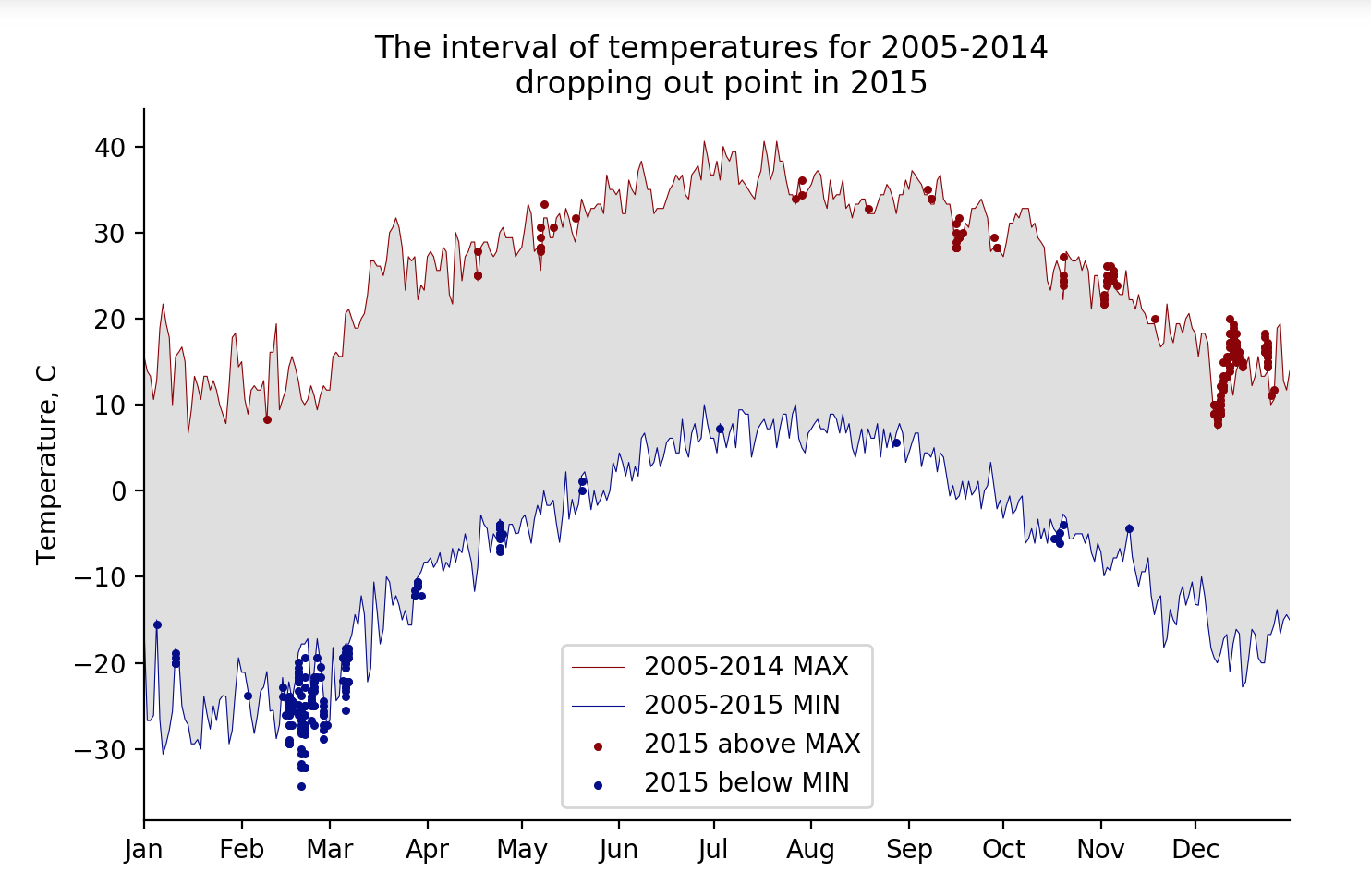
2005년부터 2015년까지의 미국 일부 지역의 일별 온도 데이터에서 2005-2014년은 각 월일에서 최대 최소 온도를 각각 이어서 line graph를 그리고 그 사이를 회색으로 채웠답니다. 그리고 2015년 데이터 중에서 이 회색 범주에 들어가지 않는 친구들을 scatter plot했구요, 범례와 각 축과 타이틀을 채우고 디자인적으로 이쁠 수 있으면 chart-junk를 최소화 하기 위해 위쪽과 우측에 축도 invisible하게 해봤네요.
이렇게 한 번 과제를 하고 나면 뭔가 내용들이 저한테 스며드는 느낌이 들어서 괜시리 뿌듯합니다.
소스코드가 궁금하신 분들은 댓글 달아주시면 알려드릴게요.. Honor code를 지켜야해서..
자, 그럼 이제 진도를 나가보죠.
이전까지 했던 것들에 이어서 이번에는 subplot과 histogram을 matplotlib을 이용해서 그려볼게요.
아 참, 이전포스팅까지 matplotlib함수를 써서 plotting할 때는 항상 %matplotlib notebook 이라는 것을 썼었는데요.
이는 jupyter notebook에 inline으로 plot을 보여준답니다. 이외에도 tk나 qt5를 통해서 새로운 gui로 볼 수도 있어요.
그럼 바로 어떻게 subplot을 그리는 지 코드를 볼까요.
import matplotlib.pyplot as plt
import numpy as np
plt.figure()
# subplot with 1 row, 2 columns, and current axis is 1st subplot axes
#()안의 숫자는 순서대로 row의 갯수, column의 갯수, 그리고 지금 표현하고자 하는 plot의 위치를 정하는 코드입니다.
plt.subplot(1, 2, 1)
linear_data = np.array([1,2,3,4,5,6,7,8])
plt.plot(linear_data, '-o')
exponential_data = linear_data**2
plt.subplot(1, 2, 2)
plt.plot(exponential_data, '-o') #이렇게 그려주면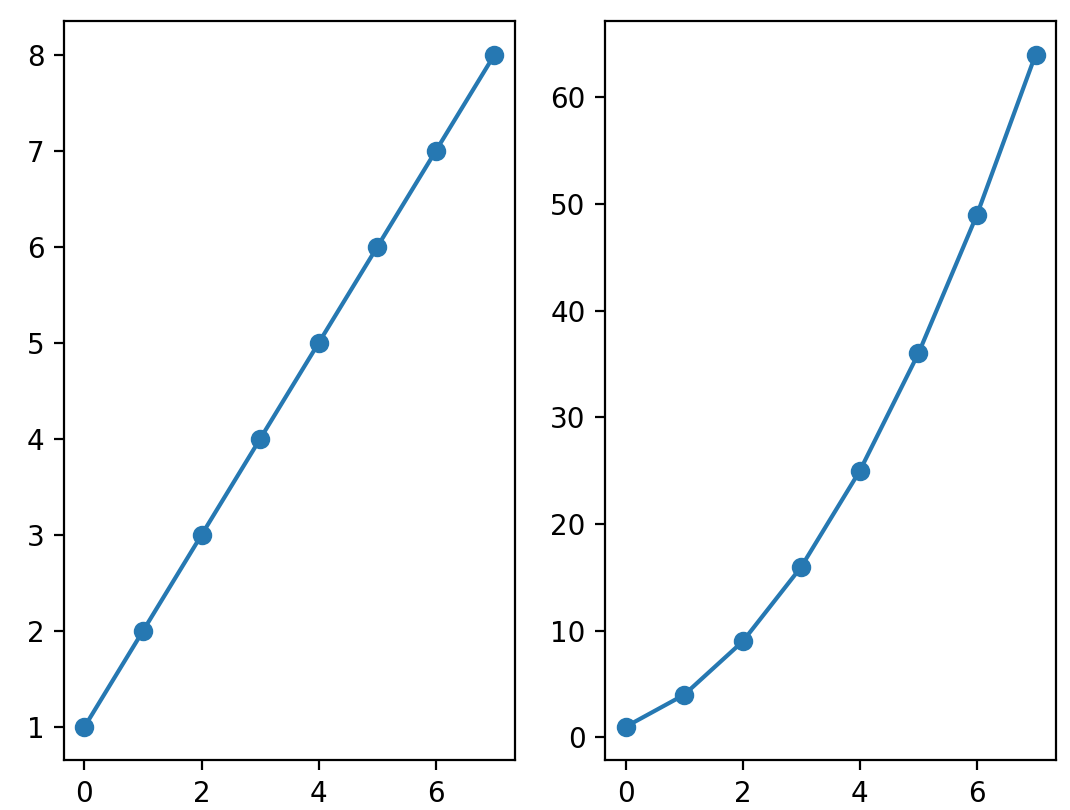
이렇게 한 개의 row에 두개의 column으로 채워진 subplot을 그릴 수 있어요.
하지만 저희가 주로 subplot을 그리는 이유는 경향성을 보기위함도 있겠지만 여러 plot들을 비교하기 위해서일텐데요.
그러기엔 y축의 범위가 다르네요. 이럴 땐 어떻게 할까요?
plt.figure()
ax1 = plt.subplot(1, 2, 1)
plt.plot(linear_data, '-o')
# pass sharey=ax1 to ensure the two subplots share the same y axis
ax2 = plt.subplot(1, 2, 2, sharey=ax1)
plt.plot(exponential_data, '-x')
이렇게 sharey혹은 sharex를 통해서 각 축의 범위를 함께 통일시켜줄 수 있답니다.
그리고 뭐 추천하지는 않지만 plt.subplot(1,2,1) == plt.subplot(121) 이렇게 , 없이 써도 똑똑하게 알아보기도 한답니다.
그럼 이번엔 3*3 subplot과 같은 plot은 어떻게 그릴까요?
# create a 3x3 grid of subplots
fig, ((ax1,ax2,ax3), (ax4,ax5,ax6), (ax7,ax8,ax9)) = plt.subplots(3, 3, sharex=True, sharey=True)
# plot the linear_data on the 5th subplot axes
ax5.plot(linear_data, '-')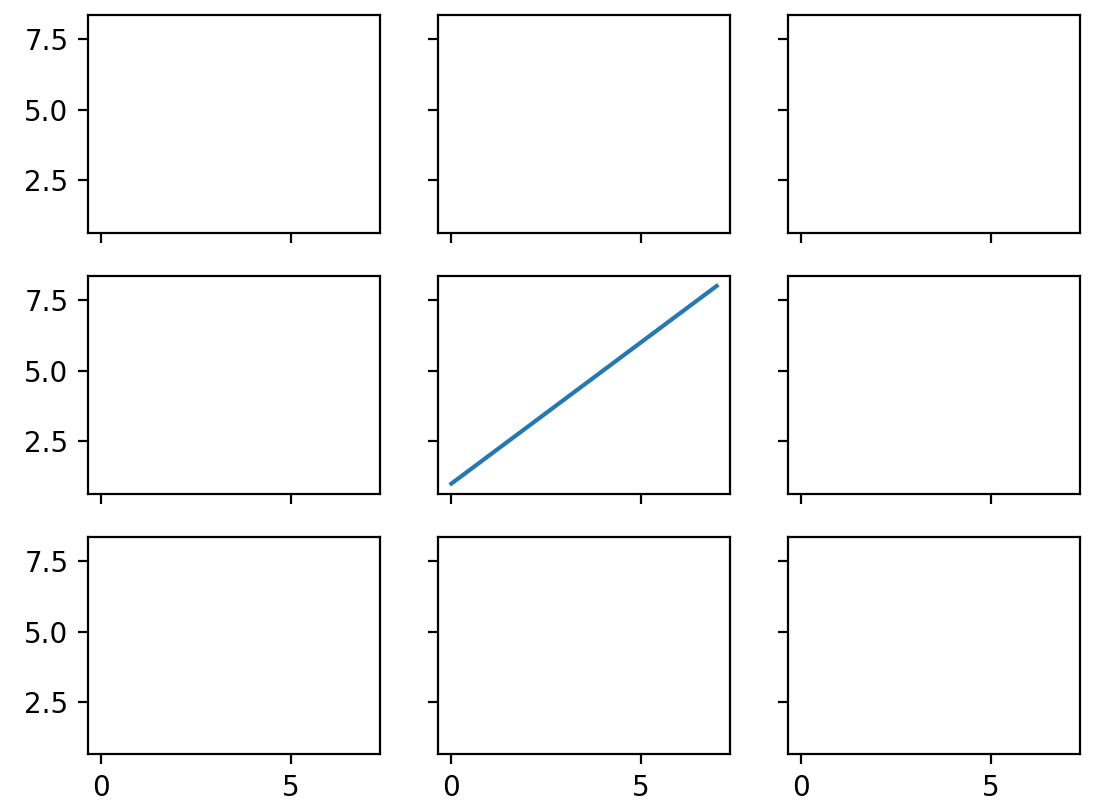
조금 생소하긴 하지만 그렇게 어렵지는 않죠?
for ax in plt.gcf().get_axes():
for label in ax.get_xticklabels() + ax.get_yticklabels():
label.set_visible(True)위의 식을 통해서 보이지 않는 axis 라벨들도 보이게 할 수 있답니다.
이번에는 Histogram을 plot하는 것에 대해 알아볼까요?
위에서 배웠던 subplot을 바로 적용해서 한번 만들어볼게요. 총 사이즈의 개수를 10배씩 늘리는 normal random distribution을 살펴보죠.
# create 2x2 grid of axis subplots
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, sharex=True)
axs = [ax1,ax2,ax3,ax4]
# draw n = 10, 100, 1000, and 10000 samples from the normal distribution and plot corresponding histograms
for n in range(0,len(axs)):
sample_size = 10**(n+1)
sample = np.random.normal(loc=0.0, scale=1.0, size=sample_size)
axs[n].hist(sample)
axs[n].set_title('n={}'.format(sample_size))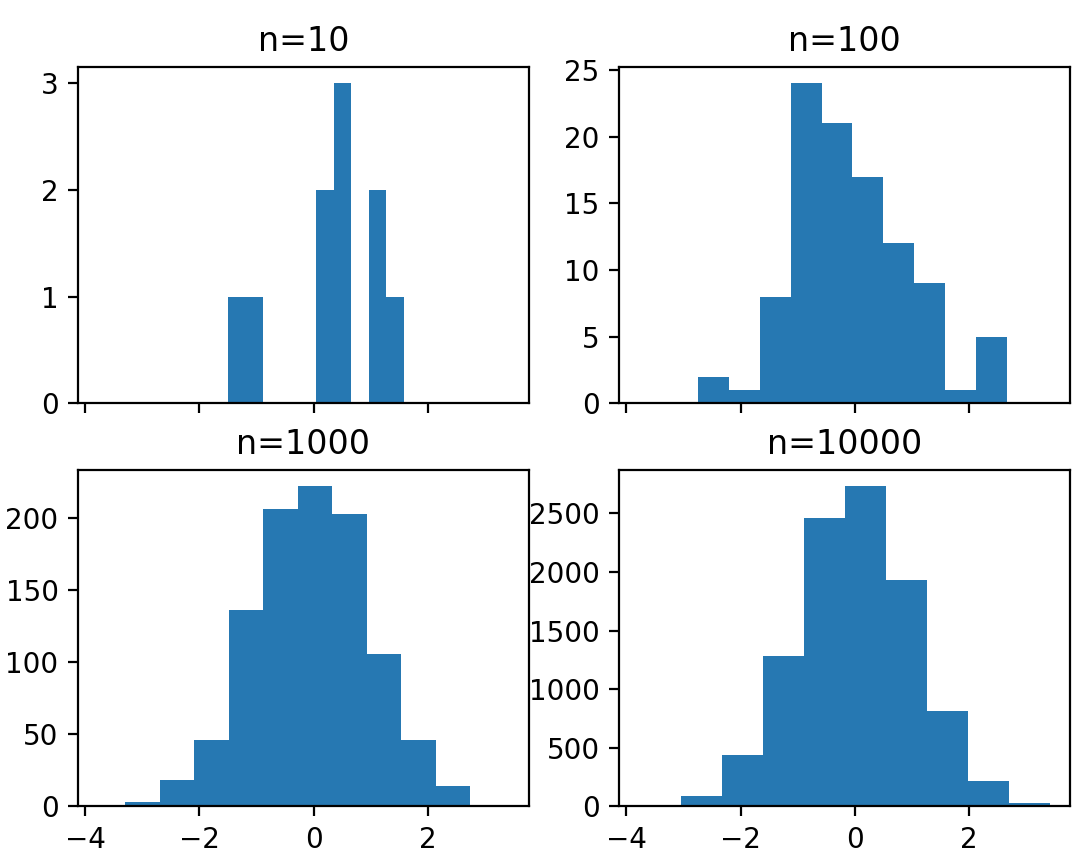
생각보다 굉장히 간단하죠? 위의 전처리 외에는 hist() function으로 간단히 표현한 것을 볼 수 있네요.
# repeat with number of bins set to 100
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, sharex=True)
axs = [ax1,ax2,ax3,ax4]
for n in range(0,len(axs)):
sample_size = 10**(n+1)
sample = np.random.normal(loc=0.0, scale=1.0, size=sample_size)
axs[n].hist(sample, bins=100)
axs[n].set_title('n={}'.format(sample_size))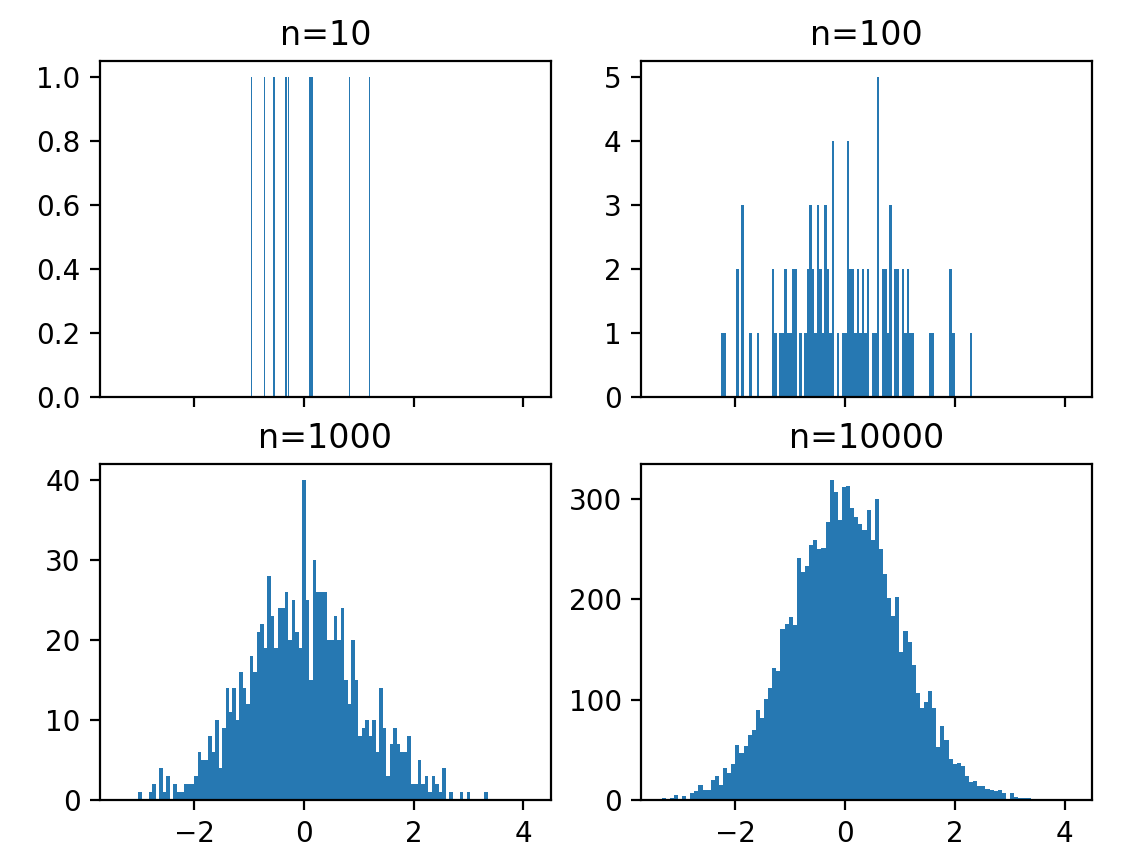
이와 같이 hist function안에 bins를 설정해줌으로써 histogram막대의 넓이 범위를 설정해줄 수도 있는데요. 막대가 너무 많아버리면 raw data와 같아져버리고, 너무 작아버리면 경향성을 파악하기 힘들기 때문에 어떻게 bin의 사이즈를 정하느냐가 histogram이용에 핵심이랍니다.
이번엔 마지막으로 gridspec의 개념을 알아볼게요.
plt.figure()
Y = np.random.normal(loc=0.0, scale=1.0, size=10000)
X = np.random.random(size=10000)
plt.scatter(X,Y)
#이렇게 X축은 random으로 된 10000개의 숫자와 Y축은 normal distribution된 10000개의 숫자가 있다고 합시다.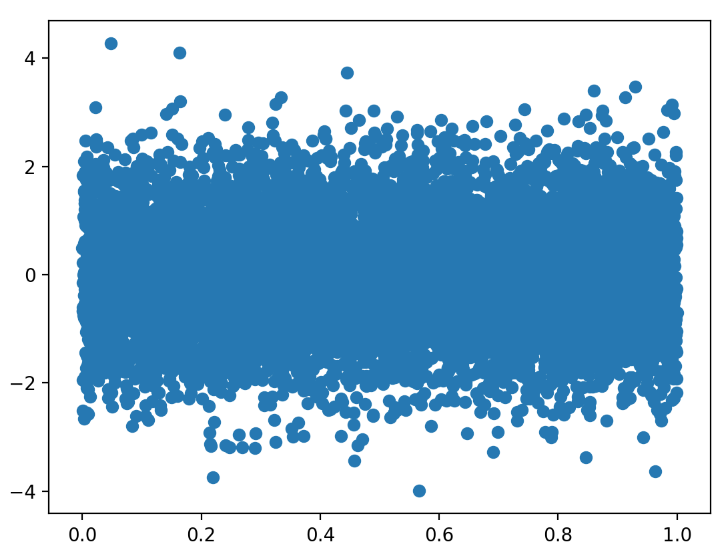
요렇게 보일텐데... 이게 무슨 데이터인지 아시겠나요?
좋지 않은 데이터표현의 예시감인데요, 하지만 이를 다시 x 축과 y축에 대해서 plotting을 해서 경향성을 알아볼 수 있게 그린다면 말이 좀 다르겠네요.
아래처럼 코딩을 한다면..?
# use gridspec to partition the figure into subplots
import matplotlib.gridspec as gridspec
plt.figure()
gspec = gridspec.GridSpec(3, 3) #gridspec을 이용하여 3,3 구획으로 나눈 후
top_histogram = plt.subplot(gspec[0, 1:]) #list처럼 범위를 indexing하여 너비와 높이를 설정.
side_histogram = plt.subplot(gspec[1:, 0])
lower_right = plt.subplot(gspec[1:, 1:])
#X, Y 위처럼 plot하되 우측 하단에 설정
Y = np.random.normal(loc=0.0, scale=1.0, size=10000)
X = np.random.random(size=10000)
lower_right.scatter(X, Y)
# clear the histograms and plot normed histograms
top_histogram.clear() #이전에 뭔가 그려져있다면 이런식으로 clear() 함수를 쓰면 됩니다.
top_histogram.hist(X, bins=100, normed=True) #normed는 값들을 normalize해주는 거에요.
side_histogram.clear()
side_histogram.hist(Y, bins=100, orientation='horizontal', normed=True)
# flip the side histogram's x axis
side_histogram.invert_xaxis()
# change axes limits
# xlim이나 ylim을 이용하여 데이터를 더 깔끔하게 표현해줄 수도 있답니다.
for ax in [top_histogram, lower_right]:
ax.set_xlim(0, 1)
for ax in [side_histogram, lower_right]:
ax.set_ylim(-5, 5)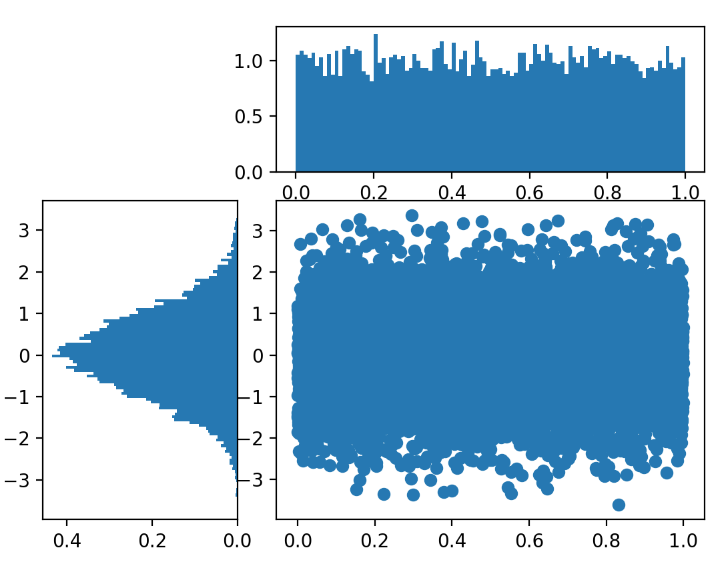
경향성이 확 눈에 들어오시나요...?
마무리는 이와 같은 gridspec을 활용한 좋은 데이터 시각화 예시로 마무리하겠습니다.
끝.
'Programming > Data mining' 카테고리의 다른 글
| 8. Animation, interactivity(인터랙티브한 데이터표현)_python (0) | 2020.02.16 |
|---|---|
| 7. Boxplot, Heatmap _ python (0) | 2020.02.16 |
| 5. Scatterplots, Line plots, Bar charts _ python (0) | 2020.02.12 |
| 4. Matplotlib Architecture _ python (0) | 2020.02.12 |
| 3. 좋은 데이터시각화를 위한 10가지 규칙 _ Ten Simple Rules for Better Figures. (0) | 2020.02.10 |

